
The default tier of AWS glacier uses tape, which is why data retrieval takes a few hours from when you submit the request to when you can actually download the data, and costs a lot.
AFAIK Glacier is unlikely to be tape based. A bunch of offline drives is more realistic scenario. But generally it’s not public knowledge unless you found some trustworthy source for the tape theory?
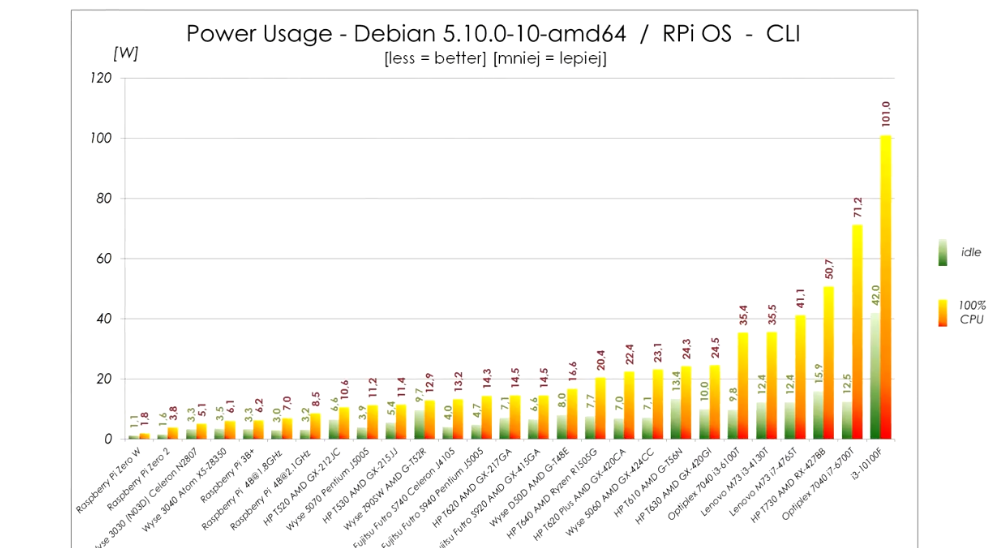
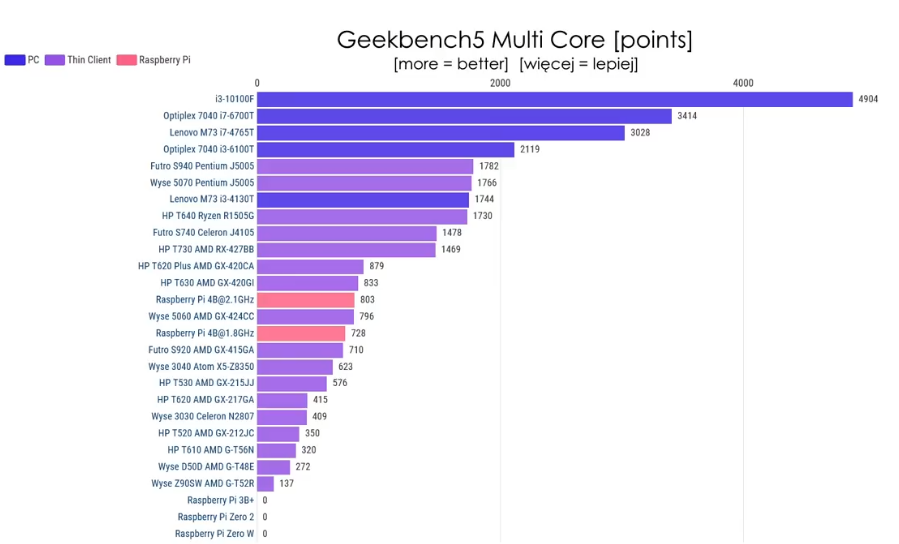


Probably not what you’re asking for, but I have an impression, that your primary motivation is curiosity and just good feeling of using the open platform, so I figured I’ll mention it.
I’m using ESP32-C3 boards with some sensors and ESPHome to monitor air quality in my house. The board is RISC-V based and can be bought for real cheap. (single digit $ price generally) ESPHome is quite easy to work with and (If you’re realistic with your expectations around very low power device) also quite powerful.
Honestly the ESPHome itself is almost too good if you’re really curious as it abstracts the differences between various boards quite well. You’re just editing a yaml file to define your desired functionality.
Even if you’re hesitant to do some soldering, you can get pretty far if you buy board and sensors with pre-soldered pins and some jumper wires.